
Welcome to our guide on understanding the ViTMatte model – a remarkable tool in the realm of image matting! This comprehensive tutorial will walk you through what the ViTMatte model is, how to use it, and some troubleshooting tips along the way.
What is the ViTMatte Model?
The ViTMatte model represents a leap in the field of image processing, especially when it comes to extracting foreground objects from images. Introduced in the paper “ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers,” the model employs a Vision Transformer (ViT) architecture to perform its magic.
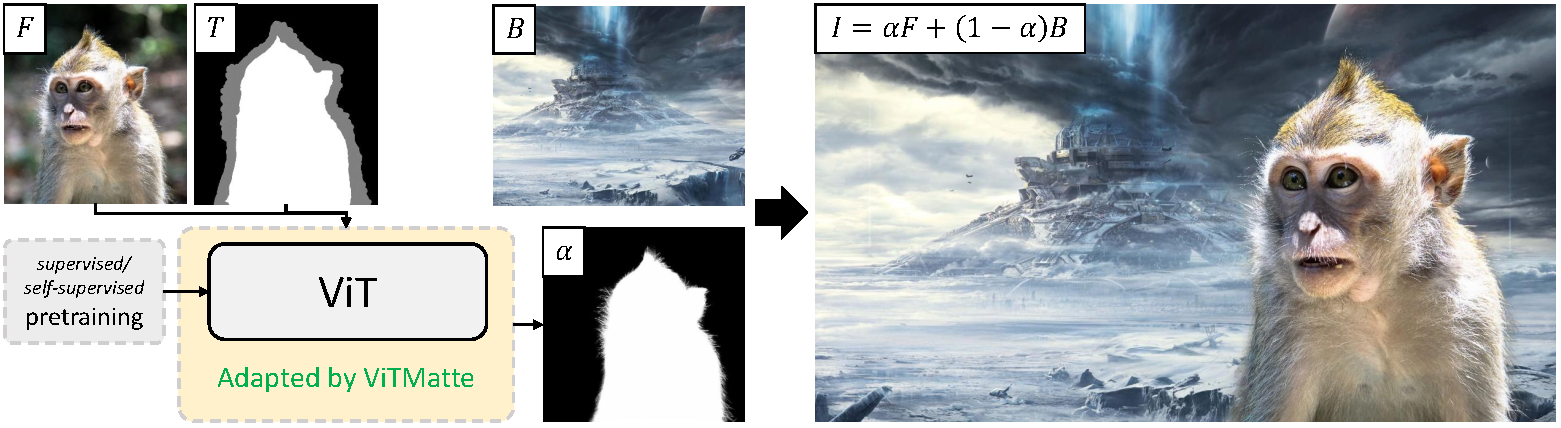 ViTMatte high-level overview. Taken from the original paper.
ViTMatte high-level overview. Taken from the original paper.
How Does it Work?
Think of using the ViTMatte model as trying to peel an onion to reveal its layers. The outer layer represents the background, while the inner layers symbolize the different elements of the foreground. The ViTMatte model expertly distinguishes between these layers by analyzing the image’s pixels, resulting in a clean extraction of the desired foreground object.
Intended Uses & Limitations
- The primary use for ViTMatte is performing image matting.
- You can access other fine-tuned versions of the model by visiting the model hub.
- While powerful, ensure you evaluate the model’s output critically, as its performance can vary based on image complexity and quality.
How to Use the ViTMatte Model
To start using the ViTMatte model for image matting, you can refer to the detailed documentation available here. For your convenience, here’s a simplified version:
# Example Code
from transformers import VitMatteForImageMatting
# Load your model
model = VitMatteForImageMatting.from_pretrained('huggingface/vitmatte')
# Evaluate your image
output = model(image)
Troubleshooting Tips
Here are some common issues you may encounter while using the ViTMatte model, along with their solutions:
- Issue: Model doesn’t load correctly.
- Solution: Ensure you have the latest version of the Transformers library. Update via pip:
pip install --upgrade transformersFor more insights, updates, or to collaborate on AI development projects, stay connected with fxis.ai.
Conclusion
In conclusion, the ViTMatte model is a powerful and fascinating tool that advances the field of image matting. By using the ViT architecture, it offers an innovative approach to accurately isolating foreground objects from background contexts. At fxis.ai, we believe that such advancements are crucial for the future of AI, as they enable more comprehensive and effective solutions. Our team is continually exploring new methodologies to push the envelope in artificial intelligence, ensuring that our clients benefit from the latest technological innovations.